
Tin Tức Mới



















Mụn luôn là nỗi ám ảnh của con người, đặc biệt là với chị em…
Xem thêm



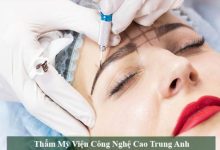

Trong vài năm trở lại đây ở Việt Nam, việc sử dụng mỹ phẩm Nhật Bản ngoại nhập đang trở thành xu hướng của nhiều chị em có nhu cầu làm đẹp, đặc biệt khi…
Xem thêm



























LearnCooking.info – Ngôi nhà ẩm thực của sự học hỏi và khám phá niềm đam mê nấu ăn! Chúng tôi…
Xem thêm
Sv388 được biết đến là nhà cái chuyên về đá gà trực tiếp online lớn nhất khu vực Đông Nam…
Xem thêm
Chỉ còn ít ngày nữa là tới Noel. Bạn đã chuẩn bị những gì để trang hoàng căn nhà và…
Xem thêm
Việc chăm sóc mẹ và bé sau sinh là một việc rất quan trọng ảnh hưởng trực tiếp đến sức…
Xem thêm
Cùng mình tham khảo những bài viết về ngày Nhà giáo Việt Nam 20-11 hay nhất. Đây không những là…
Xem thêm
Hình ảnh người mẹ không chỉ là mạch nguồn cảm hứng bất tận trong dòng chảy thi ca nhân loại…
Xem thêm
Một cơ thể khỏe mạnh sẽ tạo nên nguồn nội lực để chúng ta làm tốt mọi công việc hàng…
Xem thêm
Mụn luôn là nỗi ám ảnh của con người, đặc biệt là với chị em phụ nữ. Các vấn đề…
Xem thêm




